A hardware-software co-design to efficiently run AI on edge devices
Adjusting state space models to work with a compute-in-memory architecture demonstrated energy-efficient processing of continuous event sequences.
Adjusting state space models to work with a compute-in-memory architecture demonstrated energy-efficient processing of continuous event sequences.
A new hardware-software co-design increases AI energy efficiency and reduces latency, enabling real-time processing of continuous data streams like video or sensor feeds. The neuromorphic approach unlocks the ability to run powerful, real-time AI directly on local edge devices like phones, hearing aids or autonomous vehicle cameras, according to a University of Michigan Engineering study published in Nature Communications.
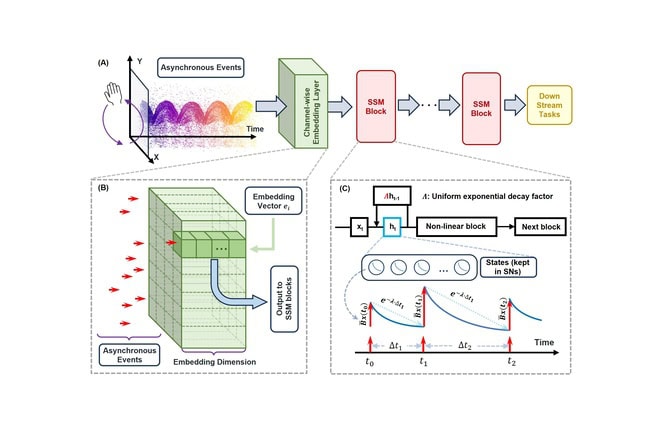
For the first time, the research team mapped complex state space models, a cutting-edge alternative to transformer models like ChatGPT, directly onto a compute-in-memory architecture.

Explore the forefront of AI
at Michigan Engineering
“Compute-in-memory systems offer very high energy efficiency and throughput, but they are rigid and not optimal for convolution and transformer networks. In this study, we showed that they are ideally suited for state space models,” said Wei Lu, the James R. Mellor Professor of Engineering at U-M and corresponding author of the study.
“All operations in a state space model can be efficiently implemented through device physics in a compute-in-memory system, potentially allowing highly efficient hardware implementation of these promising networks,” added Lu.
Running AI inference on edge devices—battery-powered devices like a smartphone, wearable health monitor or autonomous vehicle—would keep data local, improving speed, privacy and efficiency. However, current hardware and software are not efficient enough to run advanced AI on edge devices.
On the hardware side, data constantly shuttling between separate memory and processing units creates an energy-intensive bottleneck. Compute-in-memory hardware can avoid this by storing and processing data in the same location, but it is not compatible with the complex math most AI models use.
For software, transformer models such as ChatGPT demand more memory as the input or conversation lengthens, causing some long sequences to run out of memory. Models like spiking neural networks improve memory efficiency because they only activate when new data arrives, but they struggle with accuracy. The research team solved both inefficiency issues by designing a system where the hardware and software complement one another.
Previously, high-performance state space models used complex numbers. This makes chips do extra work because circuitry must track the real and imaginary parts of each calculation separately. By adjusting the state space model to only use real numbers, the researchers allow each memory cell to directly represent a piece of data, increasing efficiency.
To ensure real-time processing without memory bottlenecks, the research team set a fixed decay rate for entire blocks of the model instead of unique rates for each individual neuron. This decay rate sets the short-term memory, essentially how long the system takes to “forget” old data to make room for new information.
The state space model was implemented on a Resistive RAM (RRAM) crossbar array fabricated using a standard 65 nanometer CMOS process, providing scalability opportunities. The crossbar array, essentially a lattice structure with memristors at the junctions, performs vector-matrix multiplications to enable fast, low-power computations.
To align the hardware to match the state space model’s fixed decay rates, the researchers fabricated tungsten oxide (WOx) memristors with different thicknesses. The layers were formed by oxidizing a tungsten electrode in an oxygen atmosphere at 400 C for either 20 seconds, making a thinner layer, or 80 seconds, making a thicker layer. The thinner layer lets short-term memory fade more quickly while the thicker layer fades more slowly.
“While state space models have shown immense theoretical promise for handling long sequences, their deployment on traditional hardware has been highly inefficient. Our compute-in-memory implementation physically restructures how state space models compute, moving the field a massive step closer to highly efficient, hardware-native AI that can operate anywhere,” said Xiaoyu Zhang, a doctoral student of electrical and computer engineering at U-M and co-first author of the study.
The hardware-software co-design processed continuous event sequences with high energy-efficiency when tested through physical experiments and simulated benchmarks. The RRAM crossbar arrays performed vector-matrix multiplication just 4.6 bits away from the ideal mathematical output. During decay testing, tungsten oxide memristors matched predicted model behavior, successfully meeting the needs of the state space model.
Overall, the new design achieved real-time processing capabilities that significantly outperform conventional digital hardware in both latency and power consumption.
“Normally, transferring a complex algorithm from a perfect software environment to real-world compute-in-memory hardware introduces noise and performance degradation. However, our architecture not only maintained high accuracy but did so while slashing energy consumption. It proved that state space models and neuromorphic hardware are a naturally perfect match,” said Mingtao Hu, a doctoral student of electrical and computer engineering at U-M and co-first author of the study.
Sen Lu, Soohyeon Kim, Eric Yeu-Jer Lee and Yuyang Liu of electrical and computer engineering at U-M, also contributed to this research.
Lu is also a professor of electrical and computer engineering, applied physics and materials science and engineering at U-M.
The device was built in the Lurie Nanofabrication Facility, which is operated and maintained with support from indirect cost allocations in federal grants.
This research was supported by the National Science Foundation (CCF-2413293) and the Michigan Semiconductor Talent and Technologies for Automotive Research program.