Clinicians could be fooled by biased AI, despite explanations
Regulators pinned their hopes on clinicians being able to spot flaws in explanations of an AI model’s logic, but a study suggests this isn’t a safe approach.
5 minutes
Michigan Engineering News
Regulators pinned their hopes on clinicians being able to spot flaws in explanations of an AI model’s logic, but a study suggests this isn’t a safe approach.
Experts
Clinicians aren’t able to catch when an AI is providing bad advice, even when given an explanation of the AI model’s logic, according to a new study from the University of Michigan published in the Journal of the American Medical Association.
AI models in healthcare are a double-edge sword, with models improving diagnostic decisions for some demographics but worsening decisions for others when the model has absorbed biased medical data. Clinicians should be able to identify when an AI is providing bad advice by reviewing AI explanations, but the new study suggests that this debugging tool doesn’t work as well as regulators hope.
“The problem is that the clinician has to understand what the explanation is communicating and the explanation itself,” said Sarah Jabbour, a doctoral student in computer science and engineering and the first author of the paper published today in the Journal of the American Medical Association.
Modern healthcare is dominated by data, making it a natural fit for artificial intelligence. Clinicians hope that AI can help them synthesize large amounts of data and, in turn, improve their diagnostic accuracy.
“Determining why a patient has respiratory failure can be difficult. In our study, we found clinicians baseline diagnostic accuracy to be around 73 percent,” said Michael Sjoding, M.D., an associate professor of internal medicine at the University of Michigan Medical School and co-senior author of the study.
“During the normal diagnostic process, we think about a patient’s history, lab tests and imaging results, and try to synthesize this information and come up with a diagnosis,” added Sjoding. “It makes sense that a model could help improve accuracy.”
Given the very real life and death risks of clinical decision making, researchers and policymakers are taking steps to ensure AI models are safe, secure, and trustworthy—and that their use would lead to improved outcomes.
The U.S. Food and Drug Administration has oversight of AI-powered software used in healthcare and has issued guidance for developers, including a call to make the logic used by AI models to be as transparent as possible so that clinicians can review the underlying reasoning.
“AI models are susceptible to shortcuts, or spurious correlations in the training data,” explained Jenna Wiens, an associate professor of computer science and engineering and co-senior author of the study. “Given a dataset in which women are underdiagnosed with heart failure, the model could pick up on an association between being female and being at lower risk for heart failure.”
“If clinicians then rely on such a model, it could amplify existing bias. If explanations could help clinicians identify incorrect model reasoning this could help mitigate the risks,” said Wiens.
The multidisciplinary team designed a study to evaluate the diagnostic accuracy of 457 hospital physicians, nurse practitioners, and physician assistants with and without assistance from an AI model with explanations.
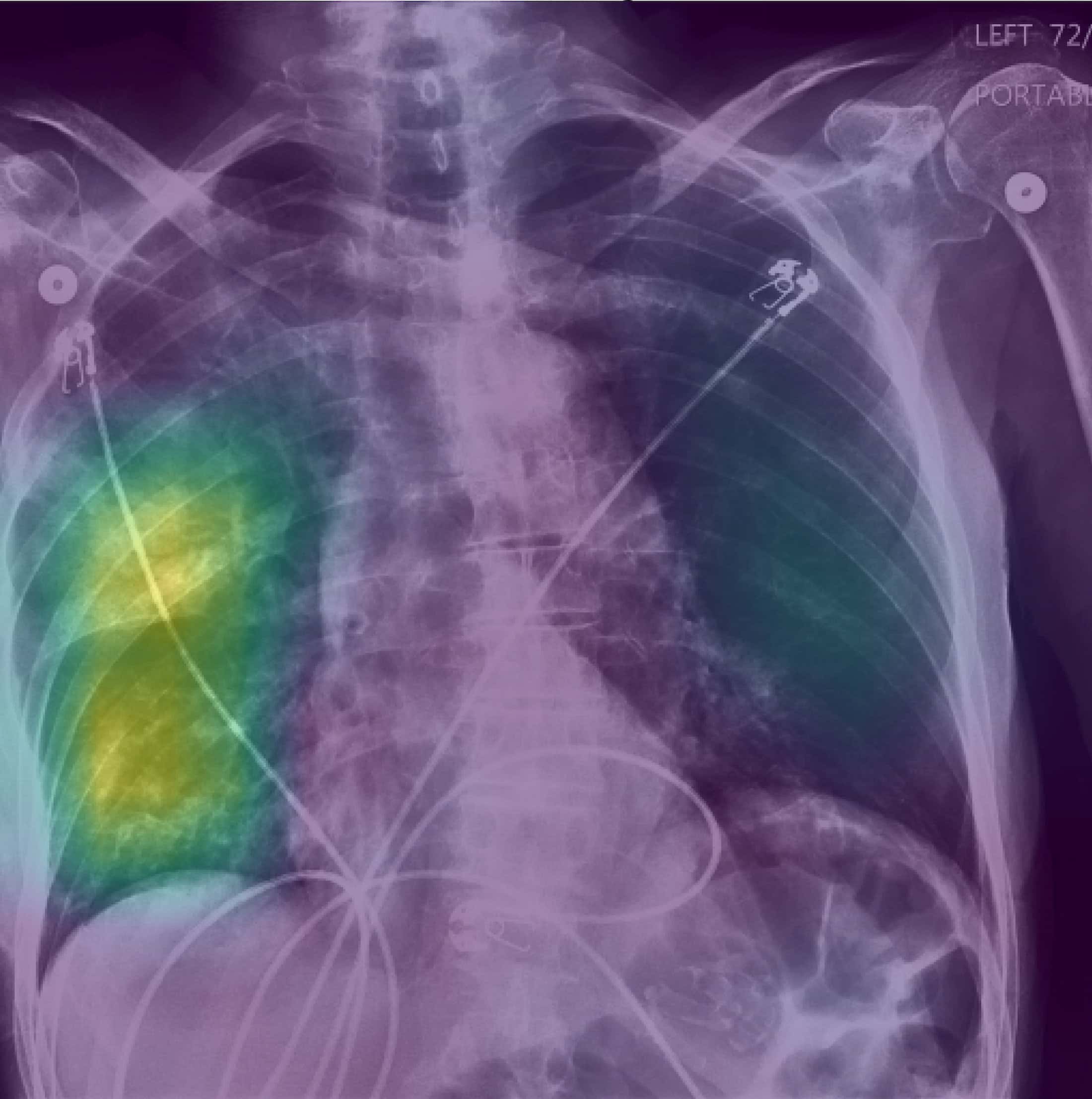
Clinicians were given real clinical X-ray vignettes of patients with respiratory failure, as well as a rating from the AI model on whether the patient had pneumonia, heart failure, or chronic obstructive pulmonary disease—all of which are potential causes of respiratory failure. Half were randomized to receive an AI explanation with the AI model decision, while the other half received an AI decision with no explanation.
Heatmaps overlaid on the X-rays served as explanations showing where the AI model was looking in the chest radiograph when making its diagnosis. When presented with these explanations alongside predictions from an AI model trained to make reasonably accurate predictions, clinicians’ accuracy increased by 4.4 percentage points. Without an explanation, their accuracy increased by only 2.9 percentage points.
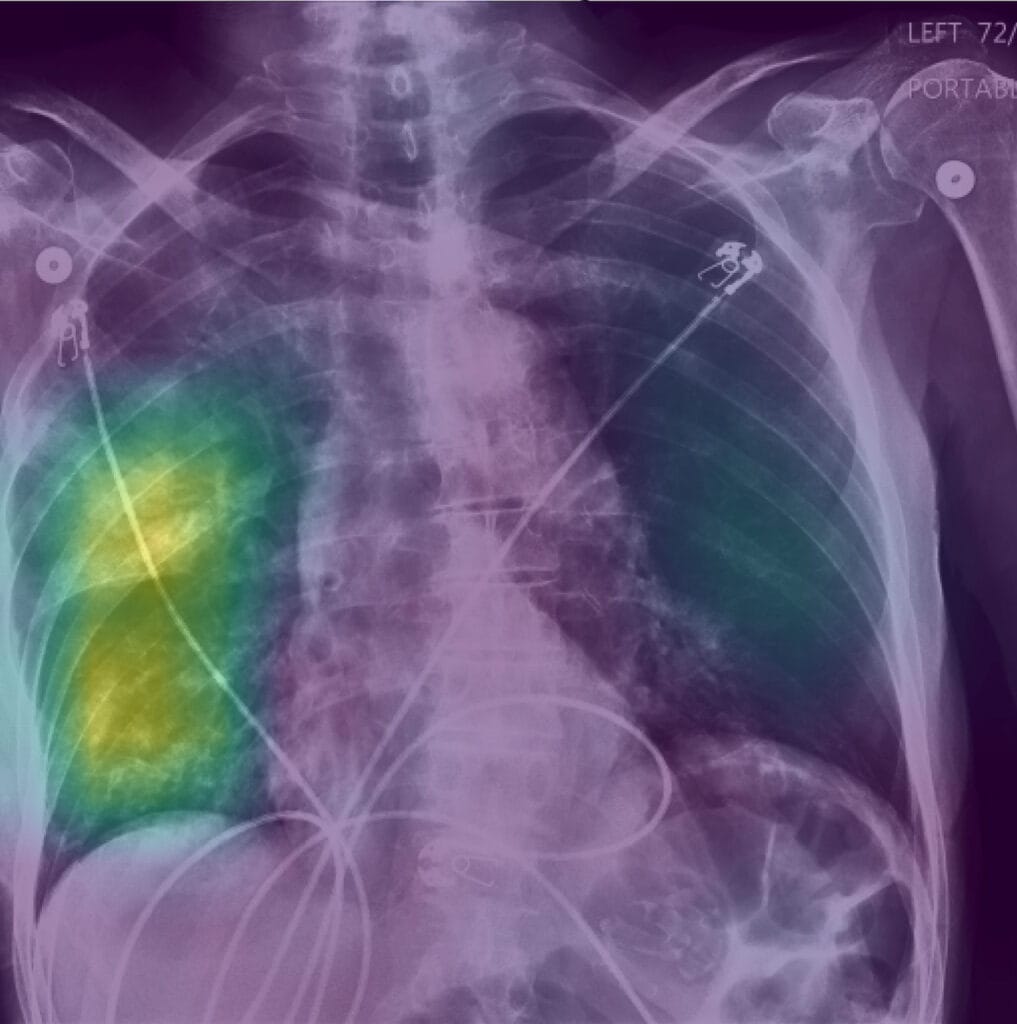
However, to test whether an explanation could enable clinicians to recognize when an AI model is clearly biased, the team also presented clinicians with models intentionally trained to be biased—for example, a model predicting a high likelihood of pneumonia if the patient was 80 years or older.
When clinicians were shown the biased AI model, it decreased their accuracy by 11.3 percentage points. The observed decline in performance aligns with previous studies that find users may be deceived by AI models, noted the team.
Explanations of the biased models explicitly highlighted that the AI was looking at non-relevant information (such as low bone density in patients over 80), yet they did not help the clinicians recover from this serious decline in performance.
“There’s still a lot to be done to develop better explanation tools so that we can better communicate to clinicians why a model is making specific decisions in a way that they can understand. It’s going to take a lot of discussion with experts across disciplines,” Jabbour said.
The team hopes this study will spur more research into the safe implementation of AI-based models in healthcare across all populations and for medical education surrounding AI and bias.
Written in collaboration with Kelly Malcom, U-M Medical School, ([email protected])
