Register for an account on just about any website or download an app to your smartphone and you likely will encounter that pesky, “I certify that I’ve read and understand the privacy policy,” check box. “Typically drafted by lawyers, these documents tell you, ‘This the information we’re collecting, this is how we’re processing it, this…
Register for an account on just about any website or download an app to your smartphone and you likely will encounter that pesky, “I certify that I’ve read and understand the privacy policy,” check box.
“Typically drafted by lawyers, these documents tell you, ‘This the information we’re collecting, this is how we’re processing it, this is who we’re sharing it with, this is how we’re storing it, and these are your options regarding the collection and processing of it,’” says Kassem Fawaz, an assistant professor of electrical and computer engineering at the University of Wisconsin-Madison. “The problem is that almost nobody reads those documents.”
Given that such privacy policies are lengthy missives filled with lots of complicated, mind-numbing legalese (not to mention presented in the tiniest of fine print), many of us scroll quickly through and click the box without a second thought. In doing so, however, we likely are compromising our privacy.
Motivated by a desire to help users comprehend the important privacy and security implications of such documents, Fawaz and collaborators from the University of Michigan and École Polytechnique Fédérale de Lausanne (EPFL) in Switzerland have developed a unique online chatbot that can answer, in simple language, questions about specific privacy policies without requiring users themselves to weed through all of the fine print.
A person working at a computer. Getty images.
“We want to help a great many people – hundreds of millions, or even billions, of people – enjoy a rapidly increasing number of mobile products and services without risking their privacy by developing and distributing scalable, easy-to-use tools,” said Kang G. Shin, the Kevin and Nancy O’Connor Professor of Computer Science at the University of Michigan.
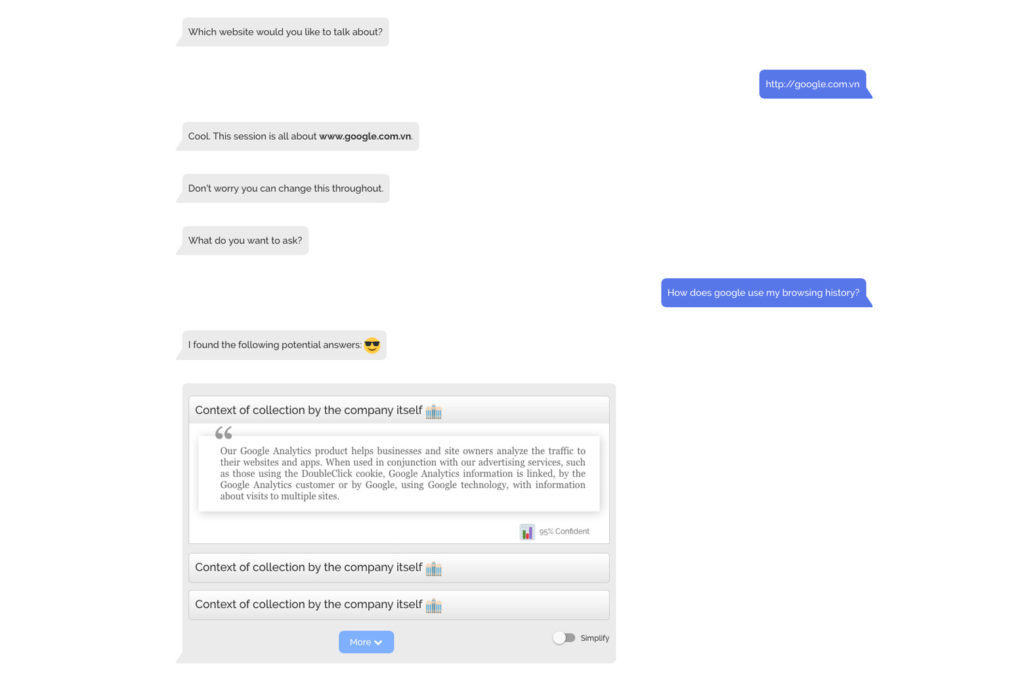
Located at pribot.org, the automated question-answering chatbot looks and functions like a text-messaging conversation with a good friend, complete with blue and gray speech bubbles and fun emojis.
Ask it, for example, how a specific popular online shopping website uses an individual’s browsing history, and the chatbot displays small, relevant portions of the site’s privacy policy.
If the chatbot can’t find the website users are asking about, it volunteers to search for and add it. Currently, the site’s database includes more than 14,000 privacy policies.
As a companion to the chatbot, the researchers also created a tool called Polisis. It shows users, in an engaging, colorful, easy-to-comprehend graphical format, what types of data companies collect, how and why they share it, how they keep that information secure, what data they store, how data from children (via networked toys, for example) is treated, an overview of users’ options for controlling the use of their information, and more. Polisis is available through pribot.org and also as an add-on or extension to some internet browsers.
A conversation with Pribot, an online chatbot that uses artificial intelligence to simplify lengthy privacy policies. PHOTO: Courtesy University of Wisconsin-Madison
Although there are commercially available privacy protection and monitoring services – including those developed by IBM and Google – they work in preconfigured scenarios or in more general situations such as discussing the weather or ordering food, says Hamza Harkous, a postdoctoral researcher at EPFL.
“When it comes to specific domains, like privacy in our case, these services are subpar,” he says. “One would have to train their own system to get any useful results.”
Training its system is exactly what the research team did.
Under the hood, Pribot and Polisis draw heavily on an aspect of artificial intelligence called natural language processing.
“It heavily builds on text analysis, or natural language processing, to automatically understand what the policy involves,” says Harkous. “As we were privacy researchers, there was a lot to learn – from the theoretical foundations of how to reason about words to the practical aspects of how to turn a policy into answers.”
In Pribot and Polisis, the researchers accounted for such factors as variations in spelling, simplifying the policy text for non-experts, and visually presenting the information without overwhelming users.
“Making the interface smooth and the system as real-time as possible was also an essential requirement for us,” says Harkous.
In other words, it’s perfect for people who might be having second thoughts about the implications of hurriedly clicking the privacy policy check box.
“We believe people really do care about privacy, and we want to help them take active steps to protect it,” says Fawaz.
The researchers are collecting data from user interactions with Pribot and Polisis with the goal of improving their performance. In addition to Fawaz, Shin and Harkous, other collaborators include Florian Schaub of the University of Michigan School of Information and Rémi Lebret and Karl Aberer of EPFL.